
这是一个好消息,如果你希望在2016年找一份数据科学的工作—在该领域职位空缺的数量正在不断增加,企业希望利用大数据来获得竞争优势。但事实上,找一份梦寐以求的数据科学工作就意味着你要具备一些技能的组合,你可能会惊讶学习哪些技能是雇主所最需要的。
最近,人们在CrowdFlower上针对Linkedin的3490个数据科学职位做了分析,并对最常出现的21个技能进行了排序。有些结果并不那么令人惊讶—SQL排在最前,而其它的结果可能是数据科学领域不断发展的领先指标。
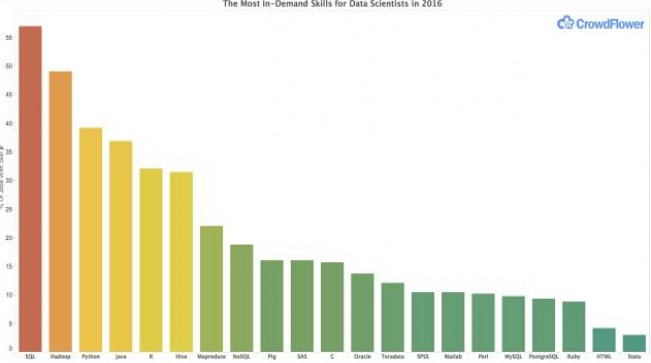
如上所述,SQL是最常见的技能,在Linkedin发布的所有数据科学工作中占比达到了57%。Hadoop排在第二,占比49%。这并不出乎CrowdFlower公司CEO和创始人Lukas Biewald的意料。CrowdFlower是美国硅谷一家从事众包数据处理的公司。
“SQL和Hadoop排在前两位并没什么惊讶的,因为它们本身就是存储数据的技术”Biewald告诉Datanami(本文转译自该网站)。“每个数据科学家必须知道如何获取数据。如果你不知如何获取数据,那你什么都做不了。”
在所有数据科学的招聘信息中,python是排在第三名的技能。在CrowdFlower去年关于数据科学家哪些技能是最重要的调查中,python排在R的后面。但在本次招聘信息的调查中(这无疑是更具有前瞻性的范围),python作为数据科学的一项关键性技能占比达到了39%。相比之下,R是32%。
相比R来说,为什么现在越来越多的雇主正在寻找具备python技能的数据科学家?Biewald提出了自己的看法:“python的工具集越来越好。已经有很多基于python的统计工具”。“还有一个认识是数据科学不仅仅是统计学”。
设想一下,数据科学家80%的时间花费在数据清理和数据准备上,而只有20%的时间是用来做分析。这或许可以解释python突然出现的原因。
“我认为Python是做数据清理的语言,而R是做分析的”,Biewald说到。在创办CrowdFlower之前,他负责领导Yahoo的搜索相关团队。“由于数据科学更多的是做数据清洗和准备,python正变得越来越重要。它无疑是将数据整理成适合做分析的数据格式最好的语言”。
事实上,Java排在第四位让人有点摸不着头脑。因为Java本身不是数据科学所要求的掌握一门语言,当你在java中写Hadoop的时候,它的高配就显得有道理了。其它跟Hadoop相关的工具都排在前10,包括Hive(31%),MapReduce(22%)和Pig(16%)。
对于这份CrowdFlower从Linkedin编辑过来的职位列表,多少有些遗漏。Apache Spark,在上面给出的数据科学技能要求中没有出现过。Scala也没有出现过,它是在Spark框架内处理数据的主要途径之一。
这可能是因为Spark还比较前沿,大家对它知之甚少。“现在周围对它有很多炒作,但可能还是太早了”Biewald说到。“在CrowdFlower,我们已经开始使用它了。我认为这门技术很棒,但在企业真正使用它的时候会有些滞后”。
Spark和Scala可能是数据科学的未来(它们在Alphabet[NASDAQ:GOOGL]公司中得到大力支持,硅谷的许多高科技公司也在广泛的使用它们)。但不是每个数据科学项目或团队都需要走在技术的最前沿才能实现他们的大数据成果。“令人惊讶的是现在很多人都在寻找数据科学家,但是我认为他们中的很多人是不想走在最前沿的”Biewald说到。
这份CrowdFlower列表中包含了许多知名的数据分析工具,包括SAS(占比16%),SPSS(10%),Matlab(10%)和Stata(占比3%)。Biewald认为这些工具仍是有价值的并且在未来一段时间内还会继续使用。但是他希望它们的市场份额逐渐被那些专门为大数据设计的新工具所夺走。
“数据科学的角色大于统计学家”他说。“在我们的脑海里,这些旧的语言更多的是建立在统计学家的基础上,它们只是对少量的数据进行分析。而排名在前的Hadoop,python和Java则可以运行TB级的数据。你可以用SAS,SPSS,Matlab来做大数据分析,但这不是它们设计的目的”。
不是每个人都同意“数据科学”或“数据科学家”应该做什么以及应该掌握什么样技能的定义。事实上,一些人反对使用术语“科学”,而宁愿用诸如“应用统计”的短语。(想起了哈佛商业评论称应用统计学家是21世纪最性感的职业)
但在Biewald和其他人眼中,处理数据的能力和统计分析的能力同等重要。这就是他对数据科学家进一步给出的定义。
“在过去,我们处理几千条记录的时候不是特别难。但是,当数据量达到数十亿条记录的时候我们就需要真本事来得到一个规范的格式,以便我们进一步做回归或机器学习”他说。“对于这种情况,我想要聘请的是一名掌握python或者是C、Perl、Ruby亦或是一门更多做数据处理而不是做数据分析的语言的数据科学家”。
原创文章,作者:爱运营,如若转载,请注明出处:https://www.iyunying.org/seo/dataanalysis/48641.html