本文整理自QCon北京Fangjin Yang的英文主题演讲。
演讲整理:刘继伟
在QCon 2016 北京站上,Druid开源项目的负责人,同时也是一家位于旧金山的技术公司共同创始人的Fangjin Yang杨仿今老师分享了题为 《Evolution of Open Source Data Infrastructure》的主题演讲,在演讲里杨老师详细的介绍了开源大数据的过去,现在的形态以及未来几年发展的趋势和方向。本文根据他的演讲整理而成。
首先,介绍两个使用案例。
第一个是OLTP流程,主要指的是整个商业应用和流程。我们会收集交易数据,在业务过程当中收集数据,比如要销售一些网上产品,可能希望把每一单都能够记录下来。
第二个主要案例是OLAP,主要指的是分析数据,我们让所有收集的数据能够有意义,可以帮助我们生成报告,根据数据分析,进行业务决策。这个应用场景下,我们会把一些数字,比如说收益,将整个数据维度Dimensions以及Measures和数据整合在一起。
Small Data Analytics
在一个小数据里可以做以上两个应用,单个系统都可以应用,非常简单。我们主要做什么呢?我们会像微软表格当中收集数据,之后进行一系列视觉化。

我们提供的解决方案对于小的数据而言主要使用单个系统,这个单个系统主要通过一个系统解决所有的问题和所有的应用场景,而且能够快速提取出关键数据,并且很容易的去创建各种不同的数据展现形式。
在过去几年里,数据一直在快速发展,人们意识到有些解决方案针对小数据已经无效了。数据已经不能够通过一台机器或设备来解决,所以我们需要通过多台设备共同来解决大数据的问题。
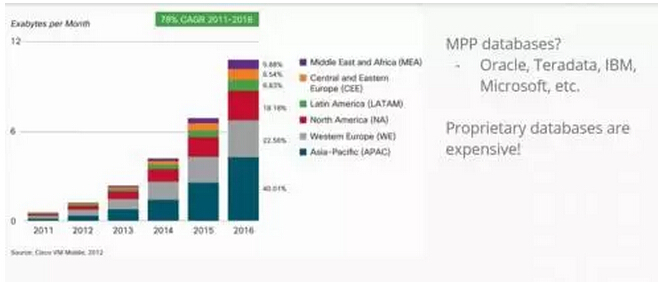
当数据快速发展的时候,当时我们确实也存在很多数据解决方案,这些解决方案主要是由IBM等等公司提供。这些解决方案看起来非常并行,是企业数据的解决方案。但是对于这些解决方案存在的问题就是针对专属的数据,要付出高昂的代价解决这些问题。在大数据世界里,很多中小公司也会产生大量的数据,他们无法支付得起高昂的企业解决方案。
The rise of Hadoop
1.history of Hadoop
2003年,谷歌发布了一篇Google GFS论文,论文介绍了如何将GFS系统用于大型的、分布式的、对大量数据进行访问的应用。2004年,谷歌公布了另外一篇关于MapReduce的介绍一种用于大规模数据集(大于1TB)的并行运算编程模型,即MapReduce编程模型。
2005年初,雅虎启动了Nutch项目,同时,Nutch项目的开发者在Nutch上有了一个可工作的MapReduce应用,到当年年中,所有主要的Nutch算法被移植到使用MapReduce和HDFS来运行。
在2006年2月,他们从Nutch转移出来成为一个独立的Lucene子项目,称为Hadoop。大约在同一时间,Doug Cutting加入雅虎。Yahoo提供一个专门的团队和资源将Hadoop发展成一个可在网络上运行的系统。
2008年1月,Hadoop已成为Apache顶级项目,证明它是成功的,是一个多样化、活跃的社区。通过这次机会,Hadoop成功地被雅虎之外的很多公司应用。
今天有很多不同的技术存在于整个大数据的技术空间里,大多数的技术像Hadoop一样都是开源的技术。很多人当他们最开始关注大数据空间的时候,他们觉得太复杂了,他们很难理清每个系统到底做什么的,或者他们应该什么样的系统解决现实存在的问题。
2.Early Open Source Stacks
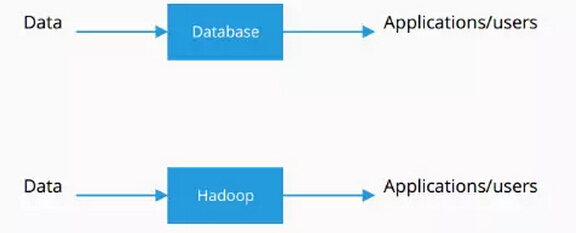
早期的应用都是直接现将数据存储到数据库中,应用/用户直接/间接从数据库中获取所需数据。

随着数据量的增大,人们开始关注Hadoop进一步替代他们使用的传统方法。Hadoop有两个重要的组成部分,一个是存储引擎,这都是以谷歌HDFS作为依据,一个是数据处理模型MapReduce。Hadoop是一套很灵活的解决方案,它也是最常用的一种数据处理方式。但是它在某些方面表现的比较乏力。
3.Rise of Open Source Data Infrastructure

当一项技术变得被广泛采纳的时候,那么他的局限性也变得众所周知了,Hadoop也不例外,下文罗列了Hadoop的部分缺点
1)、快速查询;
2)、(流式)事件的传递;
3)、流处理;
4)、内存计算
为了解决Hadoop的缺点,许多新的技术被创建出来。
Data Infrastructure Space Today
1.Modern Open Source Stacks
当下的数据处理模型如下图所示:
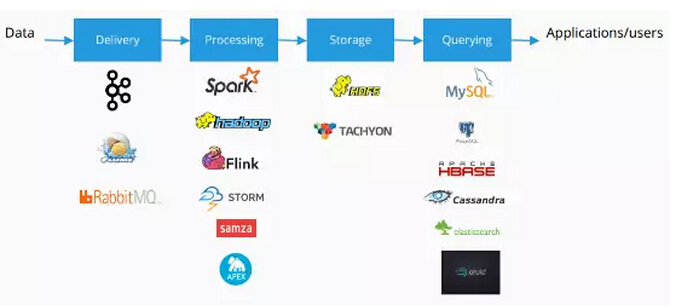
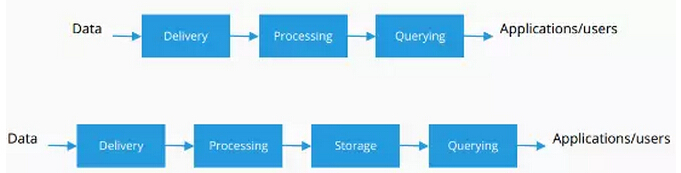
当我思考当今的大数据现状的时候,大多数技术都会归为四类,第一个是整个传输数据,第二加工数据,第三存储数据,以及数据的问询或分析。现在关于技术有很多不同的领域,因为谈到大数据的时候,人们已经意识到即使简单的问题也需要很多复杂的解决方案,和一种专署的技术,或者大规模的技术才能够解决。比如说从一个位置向另外一个位置进一步传输数据的数据是比较简单的,但对大量数据就是非常复杂的问题了,这些都需要非常先进的技术才能够解决。
所以这四类技术所有的开源的大数据技术都可以归为四类当中的一类技术,很多人都已经开始意识到不同的技术其实可以结合到一起,把它用为一种端对端的技术来对所有的数据进行分析,我会给大家介绍一下四种不同的技术。不同的技术在整个大数据空间如何归为四类当中的其中一类。
这里有很多的不同技术,有很多技术都是彼此竞争关系,我没有时间给大家做逐一赘述,也不能够进一步详细介绍每个技术是什么。但是我希望给大家提供简介,帮助大家了解这些技术是做什么的,以及整个构架是什么样的。
2.Data Delivery

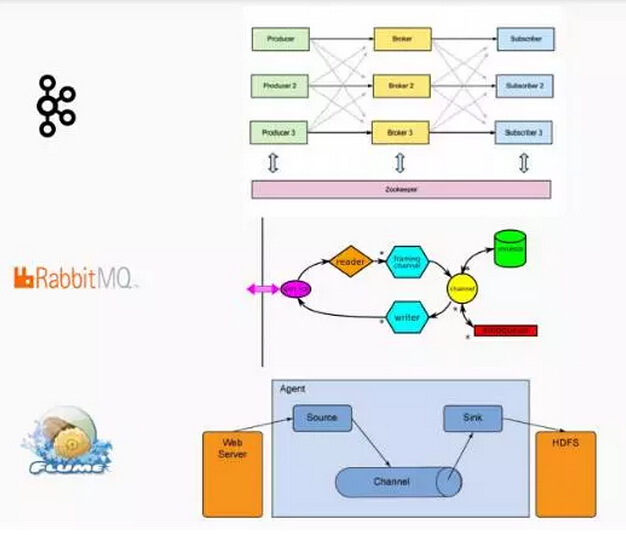
第一类技术是数据传输系统,数据传输系统他们主要负责把事件从一个位置进一步运输到另外一个位置,所以我们可能会产生一些数据的,比如说把数据进一步传到整个数据系统。数据传输系统他们主要专注于短期储存,这些系统通常会和数据流来打交道。这些系统可以分为不同的类别,每个系统都有不同的框架和不同的关键点传输数据。
但是我给大家介绍一下上层的架构,就像kafka,它提供了资源的上分区,把生产数据和消费数据直接分开,现在这个架构是根据分布式逻辑来进行的,你可以把这些数据按照分布的逻辑进行分布,之后从分布式逻辑上来收集数据,这是一个非常好的描述数据的一个方式。
MQ是提取数据的系统,不完全一样,这两个架构有些不同,不同的架构,不同的结构可以产生不同范围,不同规模的表现性能,以提升不同的操作性能。
现在Kafka逐步变成了这个领域的标准。
 3.Storage
3.Storage
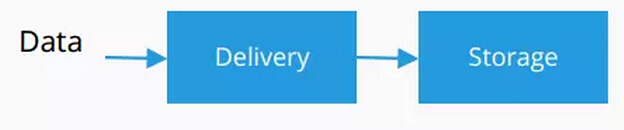
数据提供系统是怎么工作的呢?它通常把数据提供到其它地方进行进一步的处理,首先可以把数据提供到存储的机制当中,存储机制只是数据库,会存储数据,也可以从这里调用数据。然而现在更普遍的情况是一种专门的储存数据库,可以看到很多的专门的存储数据的系统。
现在最普遍的存储方式是分布式数据存储系统,也就是说把这些数据无限制地放到HDFS系统当中,随时进行提取数据。文件系统和数据提交系统有一些重叠的地方,如果你在Kafka里长时间存储数据的话,你会考虑它是一种存储的方式。但是有些时候这种数据推送,数据提供需要同样的技术。
4.Processing
数据处理的技术是做什么的呢?也就是说它把数据进行变化,让它更简洁,或者把数据进行变形,以便于更容易的处理。在查询和数据处理方面也有一些重合。我们应该这么理解,处理过程是把数据进行变形,输出的数据和输入的数据量是一样大的,查询系统的输出数据比输入数据比较小一些,这在很多的系统里都是这样的。在大数据系统方面你可以看到这些系统不断来增强处理的性能。另外一些系统重点放到查询方面技术的提高。
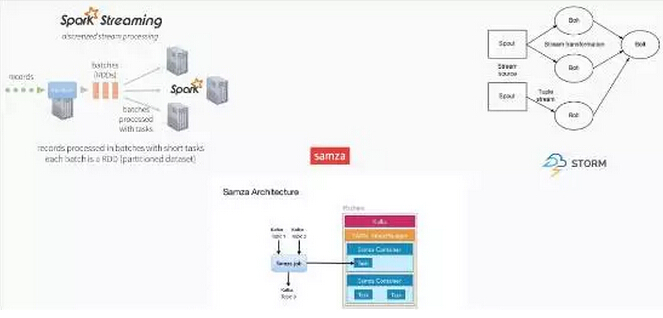
5.Stream Processing
有两种子类型,关于处理的,第一个流处理,流处理也就是把数据放到一个流的程序当中进行连续处理。首先数据提供到Kafka里,需要先进行流处理,之后才进入存储器进行存储。还有一种就是直接放到查询系统当中,这是两种不同流处理的流程。
有很多不同的流处理的处理器,有很多的开源的流处理的程序,下面这三种是非常流行的处理方式。
6.Batch Processing
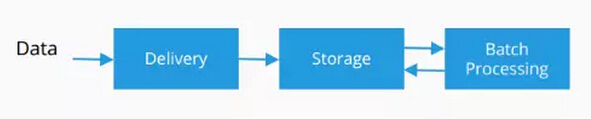
现在我要给大家介绍批处理。批处理方式在流处理方面当中不是一种真正的流处理的方式,它只是以批的方式来收集数据,然后把它放到一种特定的构架下面,然后来进行批处理。这是两种不同的架构,两种表现也是不同,它们担心的问题也不一样。通过流处理可以得到非常快速处理的结果。
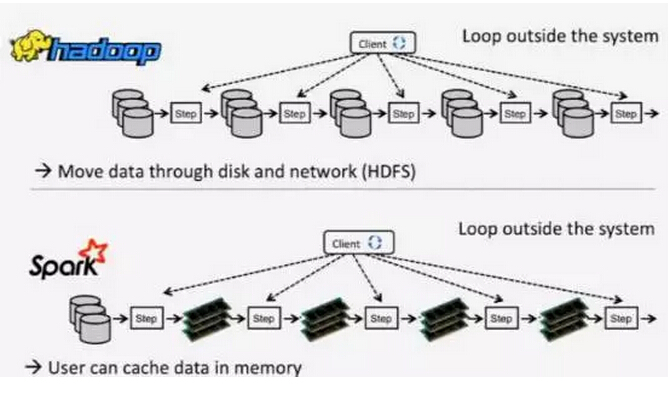
现在有两个非常流行的技术,他们分别是Hadoop和Spark对大型静态数据集的处理,Hadoop是批处理非常流行的一种技术,但是它有很多的局限。在过去几年当中Spark更加受到大家的欢迎。
Spark的工作方式就是考虑你的处理过程,将它想象成一个过程或者一个舞台,Spark做的就是非常有效地利用内存,每一个计算过程都会输出一个结果,Spark会把这些结果做一个统计,这种工作的方法是迭代式的,而且是非常高效的迭代式。Spark会把所有的数据都进行统一的整理,而且Spark比Hadoop的API更加有优势,所以在过去几年当中,Spark几乎慢慢地变成了批处理的标配。
7.Querying
最后一个环节要说的是查询环节,查询环节目前是最大的一个环节,而且是最先进的一种数据查询。这种查询技术的目的就是为了快速,我们如何来利用查询技术呢?我们要输入一个查询的命令,然后把这个命令进行处理,把输出的数据放到查询环节当中以便用户随时查询,这就需要我们对数据进行预处理,然后把预处理数据放到存储器当中,然后再送到查询处理器当中以便查询。
8.SQL-on-Hadoop
数据的操作语言是SQL,因此很多工具的开发目标自然就是能够在Hadoop上使用SQL。这些工具有些只是在MapReduce之上做了简单的包装。SQL-on-Hadoop工作的原理就是从某些地方提取数据,提取数据可能是分布式处理,把数据放到自己引擎当中,这样就可以控制数据,改变数据,并且创造数据。所以SQL是非常灵活的一种过程,这是它的主要的特点。
很多SQL on Hadoop都支持SQL查询的功能,SQL可以帮助你非常便捷得到想得到的数据。但是缺点是处理速度非常慢,因为中间涉及到一些过程要从HDFS提取数据,处理数据,然后再放到存储器当中。这样就会非常慢,如果需要快速反应的话,这种小的延迟期的操作还需要进一步的提升。所以我们就需要进一步提高优化存储。
9.Key/Value Stores
另一种加速查询速度的方法就是要把资料库进行优化,这样就能够打造一种非常快速的查询的架构。它可以支持非常快速的查找,也可以进行快速的写入,我们有很多时间序列的数据库都有键值存储。
键值存储有两种方式,第一个方式就是预计算,预计算方面要把每个查询命令都进行预测,然后把这些查询命令进行预处理,把数据进行预存储。左边是非常分散的数据,右边根据键入的信息进行分类,这样的话在某种程度上是非常有效的。在你预计算之后查询将变得非常之快,因为它会快速来查询一些映射。
但问题是一些数据库的预计算可能会耗时很长,有些时候预计算会花几个小时才能得到数据,所以提前进行预计算是非常省时的方式。常用的键值存储引擎如下:

以下是在键值存储进行预计算时得到的数据:
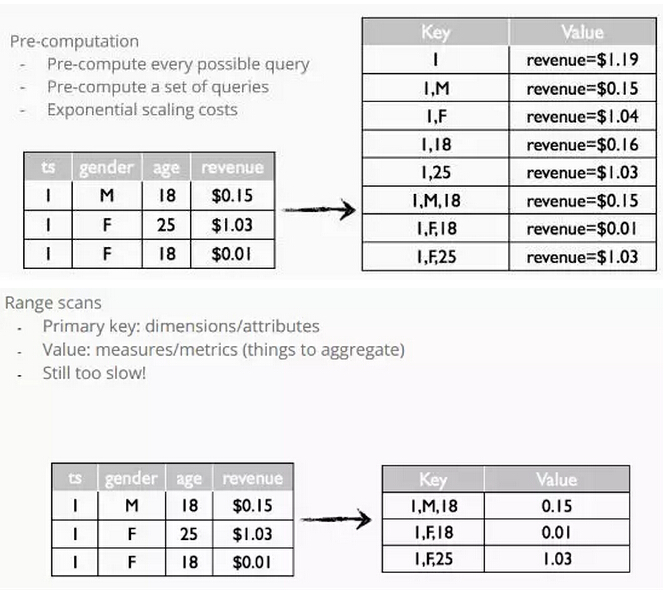
从上述的结果我们可以看出,即使是使用了键值存储,在对数据进行查询时依旧很慢。
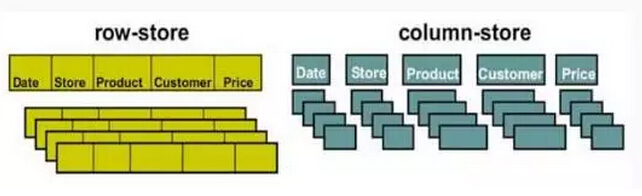
10.Column stores
另外一个方式就是,也是非常流行的技术,就是范围扫描。关于范围扫描的理念就是主间直是井号,对维度和特性进行分类,这种问题方式关于性能方面的问题。首先需要预计算的时间,这个扫描也是很花时间的。所以现在有些人仍然用键值存储方式加速查询速度,但是今年来突然出现了一种列存储的技术,马上就变得十分流行。你可以存储并且扫描你的数据,然后把这些数据进行列存储,根据查询的关键字,电脑可以快速查询各个列,这样的话你就可以在不同的列当中创造不同的关键字,以及指标。这是性能查询方面非常大的进步。
11.Druid
下面我给大家介绍一下Druid,它是一种列存储的方式,一种交互式操作系统,它会以列的形式来存储数据,它十分擅长于对数据进行并发的读取,而且也可以实现低延时的查询,在事件创建的毫秒内就可以被查询到。
12.面对如此多的选择,我们究竟选择哪一个呢?
现在大数据非常复杂,我们在评价不同技术的时候应该首先考虑的是这个技术是不是真正解决了我们的问题,其次技术是否得到了积极快速的发展,是不是有新技术的加入提升了新的功能。在不同的技术之间可能差别不是很大,我们可以随便选某一种技术来为我所用。但在未来我们可能是会有更加集中化,一体化的技术出现。
现在我要给大家介绍一下未来的发展趋势,在未来几年当中将会出现的一些技术。
我觉得开源大数据项目几乎已经达到了饱和点,可能是大数据当中一旦出现一个问题,大概就会同时出现五个解决这个问题的项目,索引很多问题都可以被快速的解决。
在最近几年中很多人都特别地注重流计算,流计算已经变得越来越流行了,在过去几年当中我们也看到很多人注意到内存计算,因为内存变得越来越便宜,在很多的系统当中内存计算可能会成为大数据处理方面的一个标配。
现在这些大数据的技术还是比较新的技术,还需要一些时间才会出现共同的标准。但是我觉得在不久的将来,我们很快就会出现大数据方面通用的标准。
我不相信有单一的一种技术会解决所有的问题,我觉得有很多不同的数据就需要有很复杂的大数据库来处理。但是我觉得未来的开源大数据的堆栈包括以下几个部分,其中必须要有一个处理单元,要有一个储存单元,当然肯定要有查询单元,没有查询单元就没有快速的目标的实现了。
在数据提交方面,Kafka已经达到了这个标准,对于流处理方面Spark已经成为了标准的工具,我觉得Druid查询方面也做得很好。
所以基础设施的架构也会不断成熟,不断地改善。在我们的架构不断变得稳定之后,会出现很多的应用,我们现在已经看到一些可视化的工具,以及虚拟现实的工具已经应用到了开源数据。
在未来几年当中还会有更多的开源数据。在虚拟现实之外,架构和设施稳定了,可以做很多很酷的事情,比如可以更多研究AR,更多研究深度学习,人工智能,这都是建立基础网络,基础系统上的未来发展,这也是非常流行的趋势。我觉得现在IT社区会变得越来越庞大。
Fangjin Yang 是 Druid 项目联合发起人、核心开发者,Imply 联合创始人。Imply 是位于美国旧金山的一家技术创业公司。Fangjin 之前曾在 Metamarkets 和 Cisco 等公司任高级工程师。加拿大滑铁卢大学电气工程专业本科,计算机工程专业硕士。
感谢杜小芳对本文的审校。
给InfoQ中文站
原创文章,作者:爱运营,如若转载,请注明出处:https://www.iyunying.org/seo/dataanalysis/76775.html