前段时间学习完了python,再加上最近需要找工作,决定爬取招聘网站(本文以拉勾网为抓取对象),通过建立相关数据模型,分析产品经理相关要求和职责,指导简历制作及今后产品努力的方向。


1、确定目标
本文以拉勾网作为抓取对象,主要在于拉勾网是互联网求职者的一个重要渠道,分析拉勾网具有一定参考意义。
2、获取数据
确定好目标好,下一步就到了获取数据源步骤。获取数据源是数据分析的前提和基础。获取数据源主要有四种常见的方式:
1. 互联网公开数据
互联网公开数据主要通过搜索获取,例如,想要获取2016收集销量排行数据,可通过输入相关关键词获取相应结果,图1 2016年收集销量排行榜,输入“手机销量排行榜2016”,得出有关销售量结果。
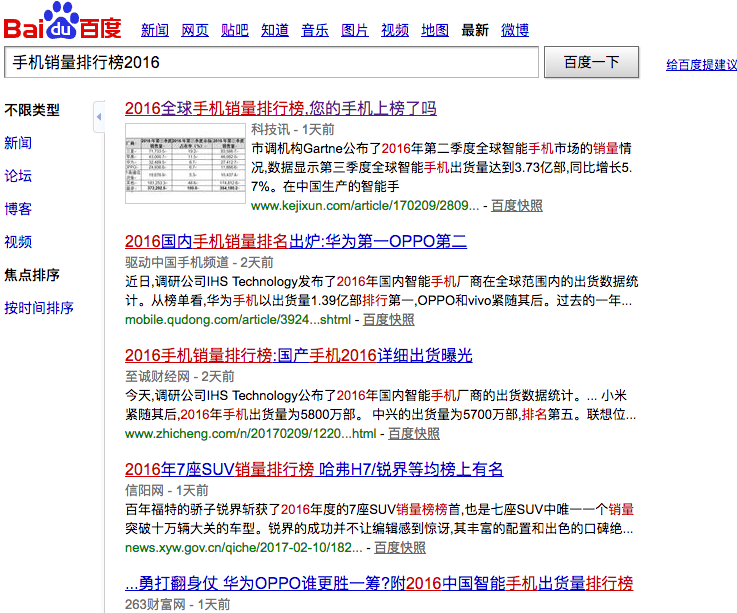
图1 2016年收集销量排行榜
当然,直接通过搜索引擎获取结果是一件比较幸运的事,不过,在获取数据时,一般不会直接获取到想要的数据。除了互联网公开数据外,本地数据也是一个重要数据来源渠道。
2. 本地数据
本地数据主要指存储在本地电脑、网盘等载体内的数据,以PDF、Word、Excel及CSV为主。例如,图2 快消品行业分析报告,收集了快消品在营销、趋势等方面的数据。
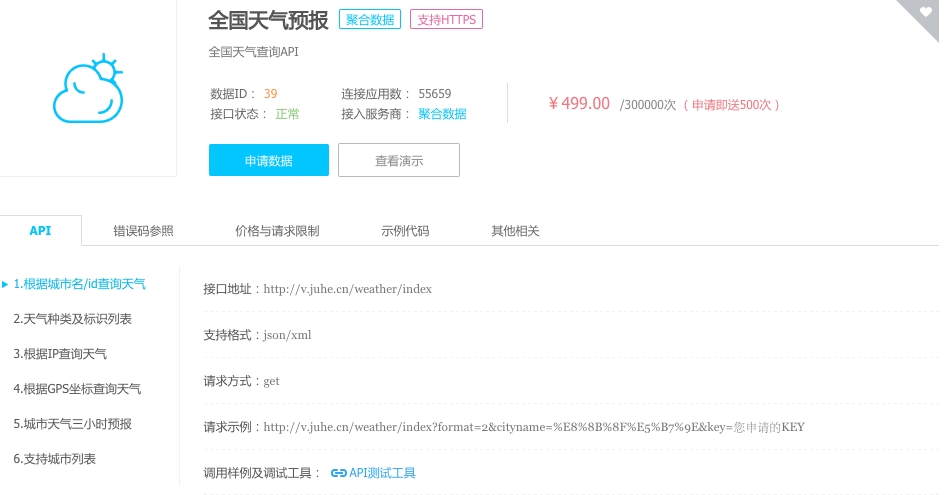
图2 快消品行业分析报告
3. API数据
API数据是一个重要的数据渠道,尤其随着互联网数据存储量越来越大以及众多网站开放了API接口,使得API接口数据成为重要形式。目前,有很多API数据应用市场,例如,百度API store ,聚合数据等,整合各种类型API,用户可通过申请apikey,获取相关数据。例如,想要获取全国天气实时数据,可通过调用天气API,获取实时数据。如图3,全国天气数据接口,申请APIkey,导入相应库,获取数据。

图3 全国天气数据接口
4. 数据库数据
数据库是存储数据的重要载体,目前,常用的数据库有mysql、sqlserver及oracle等,读取数据库数据需要sql语句。
5. 爬虫数据
数据爬取是当前获取数据的一种重要方式,通过比如用爬虫工具爬取点评网站的商家评分、评价内容等,或是直接自己人肉收集(手工复制下来),亦或是找一个免费问卷网站做一份问卷然后散发给你身边的人,都是可以的。这种方式受限制较少,但工作量/实现难度相对较大。不过,爬虫数据需要具有一定的编程基础,当前在爬取数据方面常用的是python。
本文爬取拉勾网也是采取python作为爬虫语言。本文在获取数据时,采取数据抓取的方式,着重阐述如何爬取拉勾网相关数据的。
爬取拉勾网:
数据爬取,简单的说,就是利用python写一个定向爬虫脚本,抓取北京产品经理在工作年限、学历要求及行业领域等方面的数据,通过数据数据挖掘模型,分析各个维度下产品经理相关要求。如图4产品经理抓取界面:
图4 产品经理抓取界面
通过分析检查元素-network-doc-分析http请求方式(get\post)-分析网页div、css选择类之后,选择requests、BeautifulSoup、正在表达式等工具后,开始爬虫(此处省去爬虫具体分析及爬虫过程),爬虫结束后,将爬虫结果存入本地Excel(由于数据量较少,没有使用mysql)。如图5 部分代码界面:
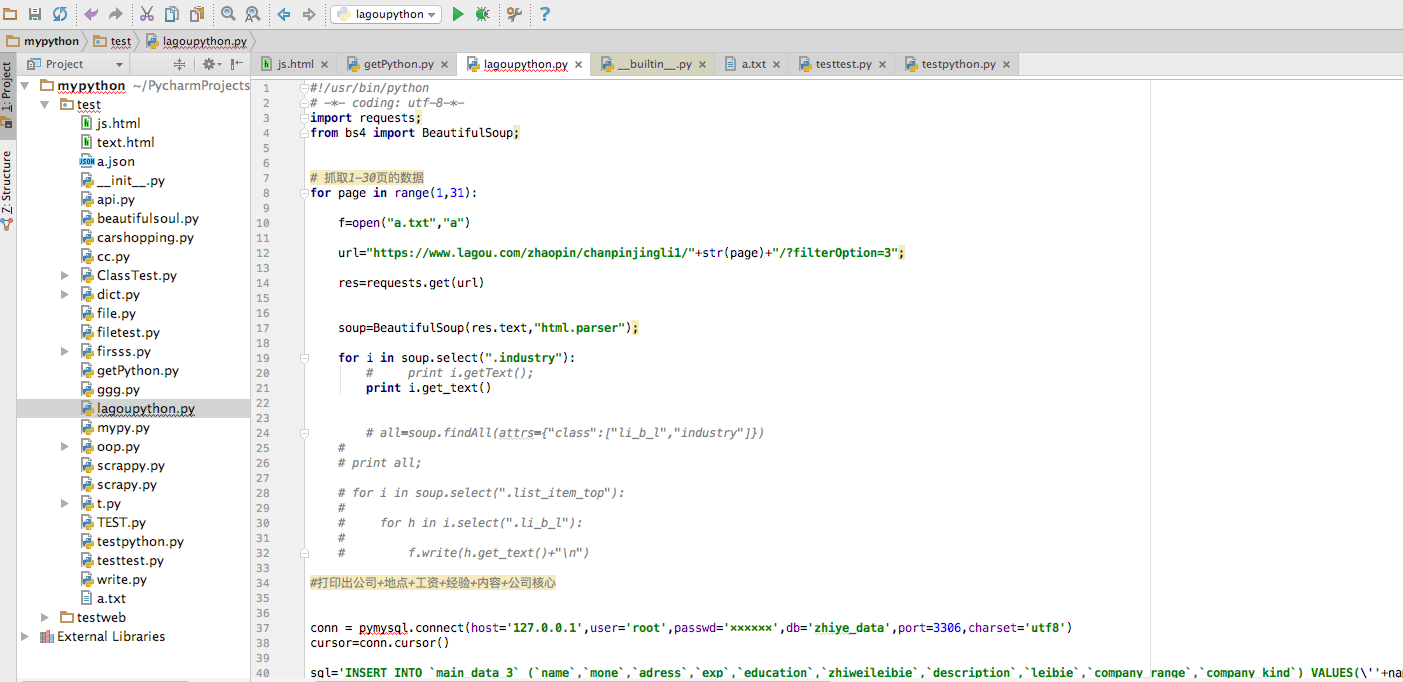
图5 爬虫结果界面
获取数据后,将数据存储在EXcel中,此时数据较乱,会出现空值等情况,针对此情况,需要进行数据清洗的过程。
3、清洗数据
爬虫获得的数据,90%以上的情况,你拿到的数据都需要先做清洗工作,排除异常值、空白值、无效值、重复值等等。这项工作经常会占到整个数据分析过程将近一半的时间。如果在上一步中,你的数据是通过手工复制/下载获取的,那么通常会比较干净,不需要做太多清洗工作。但如果数据是通过爬虫等方式得来,那么你需要进行清洗,提取核心内容,去掉网页代码、标点符号等无用内容。无论你采用哪一种方式获取数据,请记住,数据清洗永远是你必须要做的一项工作。通过对数据清洗后,下图6 数据清洗后的数据:

图6 清洗后数据
4、整理数据及分析
清洗过后,需要进行数据整理,即将数据整理为能够进行下一步分析的格式,由于数据量较少,并没有采用Spss,而是Excel。整理完相关数据后,确定分析的维度及指标,一般计算一些二级指标就可以,例如,通过计算手机销售量同比、环比等增长率。如果你收集的是一些非数字的数据,比如对商家的点评,那么你进行下一步统计之前,需要通过“关键词-标签”方式,将句子转化为标签,再对标签进行统计。当然,非数字的数据,还通常用分词统计,例如,岗位要求可以采用sae分词统计及关键词抽离等方式,抽离出关键标签及统计。
5、结 论
做完以上工作后,下一步对数据分析并制作数据报表。主要涉及到工资分配表,图7 工资分配表、图8工作经验表、图9公司简介表、图10岗位要求表。
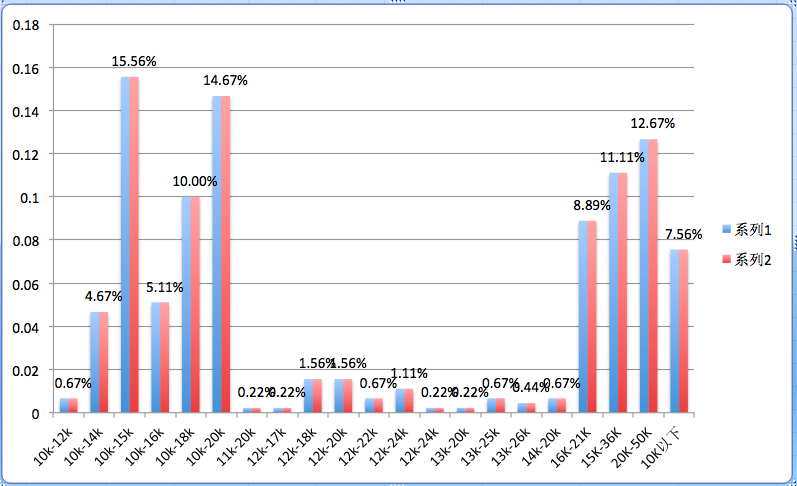
图7 工资分配表
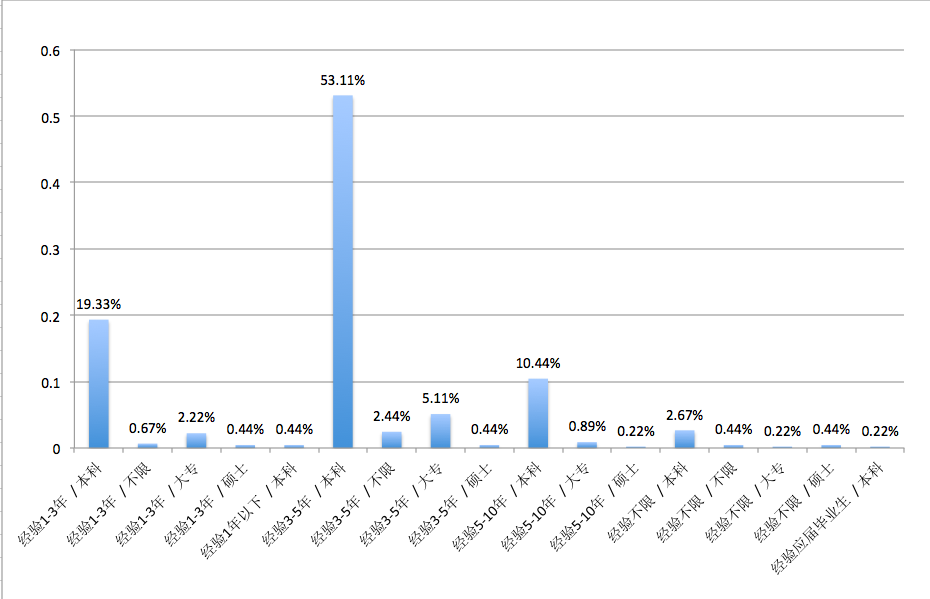
图 8-1工作经验表
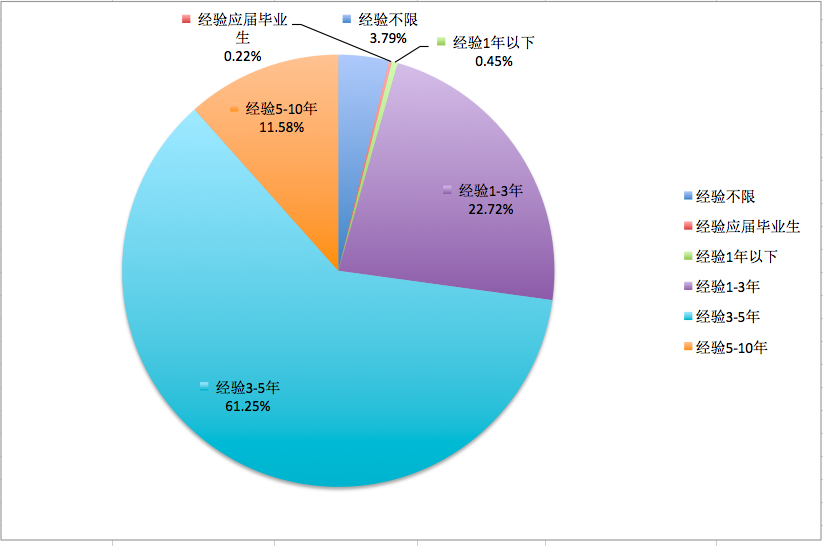
图 8-2工作经验表(年限)
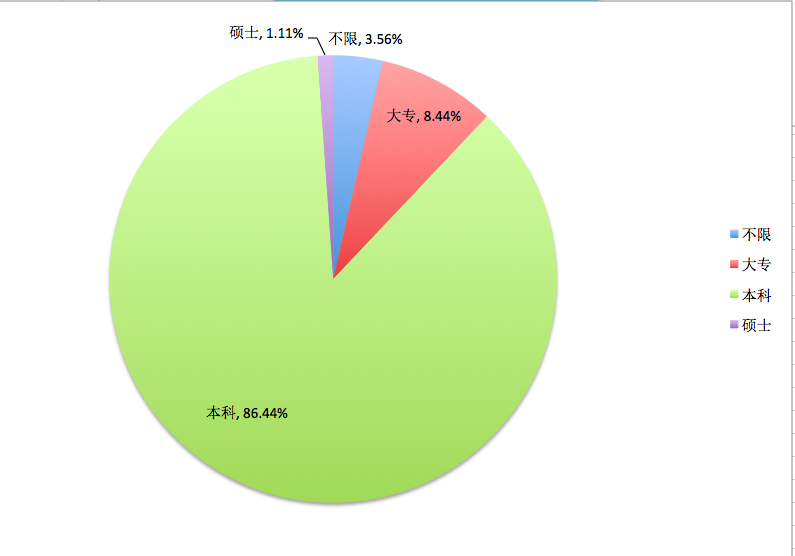
图8-3工作经验表(学历)
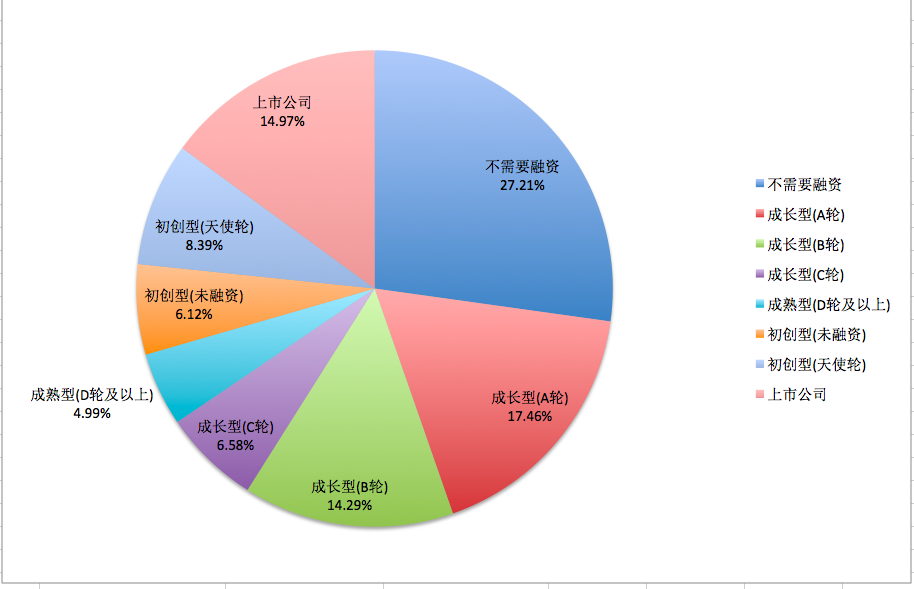
图9公司简介表
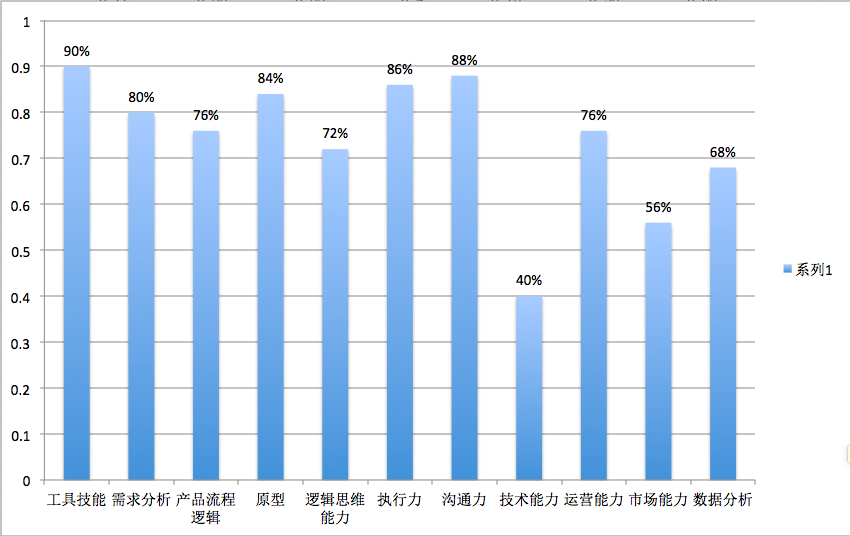
图10岗位要求表
通过图7 工资分配表可知,北京地区产品经理主要集中在10K-20K之间(此次没有对各个区间合并),工作经验主要要求在1-3年及3-5年两个区间,学历以最低本科学历为主,公司方面,以不需要融资、A轮及上市公司为主,通过岗位要求关键词提炼,工具技能(axure、visio等)为基本要求,除了基本的需求分析、产品流程外,数据分析技术能力、市场能力也是一些比较看重的。
注:时间较仓促,分析的维度及采集数据较少
作者:励秣,某公司产品经理,目前正在寻找后台或数据产品,希望有坑者“收留”,微信:15005417866。13年,985本科毕业,毕业前有近两年开发实践工作,擅长java、python,毕业后,在某知名在线租房公司一年产品运营工作,转产品近3年,且以后台为主,涉及到一些数据相关设计,希望大家帮忙推荐。
原创文章,作者:爱运营,如若转载,请注明出处:https://www.iyunying.org/pm/95477.html