
1什么是大数据?
大数据是痕迹数据汇集的并行化、在线化、生活化、社会化。
对社会学研究,我们最熟悉的是社会活动,我称其为人类活动。其实今天,不仅仅社会活动,你的私密活动也在数据之中,我没有加“社会”两个字,道理就在于人类的活动都在慢慢地数据化。在人类活动中,有一个概念叫做造痕,考古挖掘的,就是人类社会生活留下的痕迹。过去,我们通常拿这些痕迹做证据,比如考古学、历史学和社会学的许多研究活动。这些证据有一些会被数据化,数据化了的证据就叫做数据。

既然很早以前就有“数据”,今天怎么就出来一个大数据呢?一个非常重要的因素,就是网络化汇集和网络化存储,把过去的数据集中起来,这才构成了大家讨论的大数据。
那么,什么叫大数据?麦肯锡从行业和业务价值链的角度给了一个定义:数据,已经渗透到当今每一个行业和业务职能领域,成为重要的生产因素。人们对于海量数据的挖掘与运用,预示着新一波生产率增长和消费者盈余浪潮的到来。麦肯锡认为,大数据将是一个生产力的来源。今天,我们在讲“互联网+”,背后有一个非常重要的概念,叫数据驱动。过去,我们的研究活动叫理论驱动,今天,数据驱动已经变成了人类社会研究中非常重要的概念。
“大数据”概念最早从哪里来呢?没有确切的证据,但是IBM很早就开始谈大数据了。IBM给大数据的定义是“4个V”:数量(Volume)、形态(Variety)、价值(Value)、速度(Velocity)。这是从数据本身做的定义。
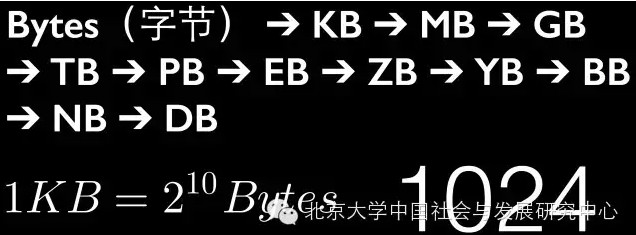
沿着IBM提出的“4个V”,先做一个简单的说明和解释。首先,从数量来看,大数据的数据量已经超出了任何个人在可接受时间范围内搜集、利用、管理和处理数据的能力了。2012年,对数据的计量已经从MB级跃升到TB级了。现在讲大数据,基本都是在PB级及以上。这个量级,超出任何单部计算机乃至大型机的处理能力。
其次,从数据形态来看,传统的数据,通常是结构化数据,大数据则是混合形态的数据。在大数据中,有一部分是结构化的数据,如SQL(结构化查询语言)数据,更多的则是非结构化的数据,如日志、音频、视频、图片和地理位置等数据,大都是非结构化的。
第三,从商业领域来看,大数据的价值密度比较低。传统的数据,通常是目标导向数据,有非常明确的价值,比如说CFPS(中国家庭动态跟踪调查)。大数据则是记录导向的,是为了记录数据而不是为了得到某个特定事件的数据,不是为了解释某个事件而记录数据。这是数据获取方式上非常重要的变化。
大数据第四个重要特征是速度。传统的数据,从测量到可用,需要相当长的时间,赫尔曼•霍尔瑞斯在统计1890年人口普查数据时,发明了读卡机,用1年的时间完成了原本耗时8年的人口普查活动;CFPS从调查结束到数据可用,也需要1-2年的时间。大数据 ,几乎随时可用,每时每刻都在记录数据,每时每刻这些数据也可用;不过,可用,也有一定的约束性。对研究而言,不是针对一个具体研究问题可用,而是说,如果你想研究某个尚未模型化的问题,可以随时截一段数据来,进行数据清理的可用。
从社会研究的视角,我自己给大数据一个定义——大数据是痕迹数据汇集的并行化、在线化、生活化、社会化。
数据汇集的并行化是一个计算机科学概念。并行,指可以同时运行很多个线程。在线化,就是数据本身在线上,不在你的桌面计算机或移动硬盘中。社会化,指每个人都有可能是数据的提供者。在过去,大多数都是由机构或者个人找“样本”提供数据;但是今天,每个人,只要接触传感器,甚至走在大街上,都是数据的提供者,同时,也是数据的使用者。生活化,则指数据的无处不在,无论是工作中还是生活中,数据始终伴随着人们。
简单地说,大数据,就是形态数字化、非结构化、在线流动着的数据,容量至少在PB级或以上,与社会行为相伴生、通过设备和网络汇集的数据。大数据是完整的,却不一定是系统的,它无时无刻都在记录着人类的行为。
因此,对社会学研究而言,大数据是一种新的研究数据来源,一种永不停息的、流动的研究资源,不一定是对其他来源数据的全面替代。
大数据和社会学研究关系密切,对其应用,目前,看起来似乎没那么紧迫,且主要对实证社会学产生较大的影响,逐渐地就会影响到社会学,甚至整个社会科学。
在社会学想象力的前提下,我把社会学的研究分为三大类。
第一类——思辨的社会学,社会学的鼻祖们,基本上都采用了思辨的方法在研究社会学。后来的,比如说帕森斯、福柯、吉登斯等也是。思辩的社会学,主要采用“概念”工具,而不讲求对概念工具的测量,这些社会学家们,基本不用数据。
第二类——诠释的社会学,从胡塞尔以降到舒茨式的现象学社会学等。这些学者,主要是围绕“意义”进行研究。对他们来说,现象的代表性或许是没有意义的,现象本身却具有意义。他们的任务,就是阐释现象的意义。这一类社会学研究,或许也不用数据。
第三类——实证的社会学,主要源于年鉴学派,也是社会学研究中作品量比较大的一类。如果把这一类社会学与前两类社会学做一个简单的区分,就在于是否使用假设检验和经验检验。
目前,数据与社会学研究关系最密切的,是第三类——实证的社会学,实证社会学研究离不开数据。
实证社会学有一个发展的过程。1998年,Platt对美国社会学研究做了一个长时段的回顾,发现:1915年-1924年,35%的社会学研究文章中用的是个案,53%用的是统计;到1964年使用统计方法的研究上升到了76%,尤其是ASR(American Sociological Review)和AJS(American Journal of Sociolog)两个主流的刊物。在今天,除非做纯粹的社会理论研究,只要涉及到社会事实的文章,似乎都需要用数据进行检验。在中国也一样,王文韬在2000年的研究,也证明了中国社会学研究实证化的趋势在迅速加强。
过去,实证社会学研究的数据主要来自于调查活动。二战以后,从密西根大学建立ISR(Institute for Social Research)开始,数据科学开始慢慢兴起。在大数据到来之前,主要有三个数据来源,分别代表了三种资源来源和三个群体的权力。第一,行政数据,各国政府、各级政府,掌握的各种ID、身份、流动、登记、就业、生产、消费等信息;第二,商业数据,比如说过去近三百年的金融数据、生产交易数据、劳动工资数据等,都在商业机构手里。直到1930s开始,社会科学家逐步认识到数据的重要性,开始寻找数据。二战以后,ISR逐步发展了一整套依靠学术力量获取数据的方法,并建立了覆盖人类社会、经济、教育、健康生活的各类调查数据。在一定意义上,调查数据,成为学者手中一项资源,也是学者在社会中发出声音的一种依据。
由此看来,从社会学研究发展的视角来看,大数据和社会学有密切关系,只是,目前看起来冲击似乎并不大,也主要是针对实证社会学的冲击。在将来可能就不是这样了,对大数据的应用不仅对社会学而言会变得十分紧迫,甚至对所有社会科学而言都将如此。
今天,社会研究依然需要通过调查获取数据。或许大数据研究的范式重在发现,而不是重在推论。社会研究的基本目标还是要把握事物之间的关系模式,不过,在大数据中,这种把握的技术变了,需要运用数据挖掘技术。不仅如此,大数据给带来的更大挑战,在于对整个教育体制的挑战。
在大数据应用日益广泛的现代社会中,进行社会研究依然需要调查数据。的确,对于大数据而言,无需调查,只需选择。调查数据,是有目的、有假设地去搜集数据。对于大数据而言,没有任何人可以做某个单一的研究假设,也没有任何人有能力做普适的研究假设。正是在这个意义上,对大数据的分析,重在发现。而且目前主要是机构性的应用,尤其是商业机构,比如阿里巴巴对大数据的应用,在世界范围内名列前茅。
如今的学术研究,还没有运用到PB级数据。社会学的研究,运用的基本上是大数据中的数据,访员不再向调查对象去搜集数据,而是向数据(机器)搜集数据。
2013年,哈佛大学的G. King教授做了一项研究,从社交媒体获得数据来看中国沉默的表达,他从1382个社交媒体网上,运用网络爬虫获取数据,是大数据中的数据。
2012年我做的“谁在开网店?”用的是淘宝600万个店家数据中的1%店家数据,也是大数据中的数据。
那么,大数据来自于哪里呢?
大数据的第一个来源,是传感器。人类社会的对传感器的运用,2005年只有1.3亿个,到2010年就发展到了30亿个,今天,大概有45亿个。什么叫传感器呢?广义地硕,任何可以监测、数据化、传输的工具,都是传感器,手机、手环、大街上的探头等,都是传感器。
大数据的第二个来源,是互联网。谷歌每天要处理大约24PB的数据,百度每天大概新增10TB的数据。
大数据的第三个来源,是社交网络。像Facebook每天要处理23TB的数据,Twitter每天处理7TB ,腾讯每日新增加200-300TB的数据,中国电信大概每天也有10TB的话单,30个TB的上网日制和100TB的信令数据。
还有,如金融、零售、科研以及政府等部门的数据。譬如,每个交易周期,纽约证券交易所要捕获1TB的交易信息。淘宝每日订单超过1000万,阿里巴巴已经积累的数据量超过100个PB。
大数据给社会学研究带来的挑战到底在哪里呢?
大数据带来的第一个挑战就是还要不要调查数据。事实上,对调查数据的挑战,取决于对调查数据的替代程度和扩大程度。相对于大数据而言,调查数据,就是小数据。大数据与小数据有一个交集,两种数据交集重叠的部分会怎么样增长,取决于两个因素,一个是传感器技术的发展,一是数据挖掘的算法技术的发展,这两项技术未来的发展,直接影响到社会科学未来发展的走向。
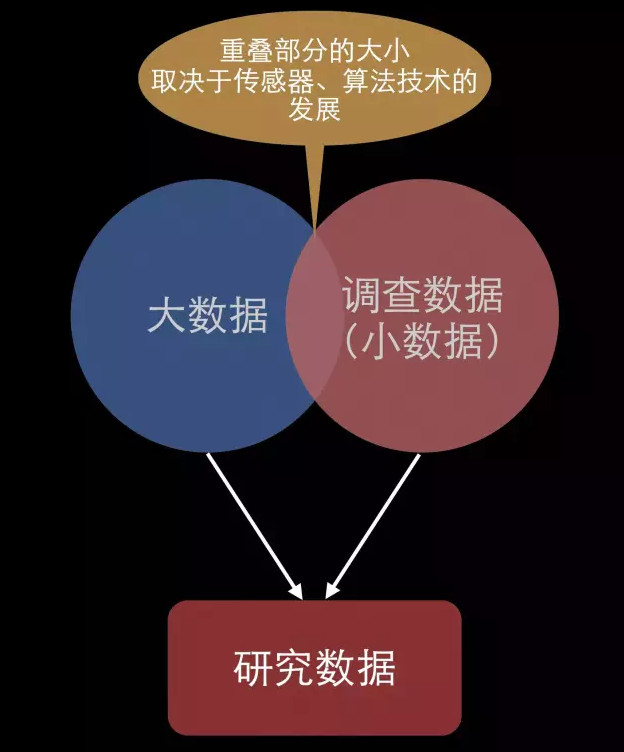
对于调查数据来说,比如说人口普查,健康调查之类的,这些调查到底干什么呢?对个体研究而言,他研究人的行为、健康、教育、成就、幸福;对于群体而言,研究群体的行动,结构和动态;对于社会而言,研究社会的状态和动态,这些研究未来有没有可能用大数据来替代?完全有可能,如果数据整合能够实现,替代的速度可能还很快!
比如,微信社交网,就是人的人情网络或人际网络;淘宝就是生活网;还有交通网,工作网,健康网。大家手腕上戴的智能手环、手机、电脑、家用电器等,这些设备如果互联互通,也会形成巨量的数据。用《信息简史》一书中的一句话来概括:万物皆比特。
数据就在那儿,问题是怎么用。未来,社会学研究对数据的利用,取决于数据化覆盖的范围。第一个覆盖的是教育,在线教育;第二个是健康,未来的健康将是完全数据化的健康;第三个是物联网,所有的器物之间连通、数据化;还有硬件、工程、制造、农业、金融等等领域,都将被数据化。既然各行各业都被数据化了,那么,大数据给社会学研究带来的第一个挑战就是:“社会研究还需要调查吗?”
对这个问题,我认为有两个点值得探讨——转换和替代。第一个是转换数据,第二个转换思维。数据的来源已经完全变了,需要调查的东西越来越少。替代,未来也有可能完全不需要做大规模调查,调查的重要性会越来越低,这是一个大趋势。
第二个挑战,社会学研究范式还有用吗?在《大数据时代》中,作者提到过去的研究范式是抽样、精确、因果。作者说,这三个过去我们为之努力奋斗的范式可能面临着革命性的转变。事实是否如此,现在依然有争论,至少这是一个值得认真思考的信号。
我自己有一个看法,运用调查数据做研究,是假设检验进行推论;运用大数据做研究,显然是通过数据进行总体归纳;方法上的确是一个本质的转换。我们知道自然科学用重复检验,社会科学没有重复检验的条件,只能做假设检验。如果数据归纳在迭代中能够满足重复检验的条件,是不是就会真正地“科学化”呢?目前,至少有一点是可以肯定的,那就是大数据研究的范式重在发现,而不是重在推论,社会研究的基本目的没有变,还是要把握事物之间的关系模式。
作者:
邱泽奇:信息社会50人论坛成员,北京大学社会学系教授,北京大学中国社会与发展研究中心主任
原创文章,作者:爱运营,如若转载,请注明出处:https://www.iyunying.org/news/15858.html
