
作者:学飞 从坠落开始
本篇综述主要参考了Liu Bing的《Sentiment analysis and opinion mining》,增加了一些自己的观点。
Liu B. Sentiment analysis and opinion mining[J]. Synthesis Lectures on Human Language Technologies, 2012, 5(1): 1-167.
摘要
近年来微博等用户自媒体的爆炸式增长,使得利用计算机挖掘网民意见不但变得可行,而且变得必须。这其中很重要的一项任务就是挖掘网民意见所讨论的对象,即评价对象。本文概览了目前主流的提取技术,包括名词短语的频繁项挖掘、评价词的映射、监督学习方法以及主题模型方法。目前抽取的问题在于中文本身的特性、大数据等。
引言
随着互联网信息的不断增长,以往的信息缺乏消失了。但海量的数据造成的后果是,人们越来越渴望能在快速地在数据汪洋中寻找属于自己的一滴水,新的信息缺乏诞生。对于电子商务来说,消费者希望能从众多的商品评论获得对商品的认识,进而决定是否购买,商家则希望从评论中获得市场对商品的看法,从而更好地适应用户的需求。类似的情况相继出现在博客、微博、论坛等网络信息聚合地。为了解决信息过载与缺乏的矛盾,人们初期手动地对网上海量而丰富的资源进行收集和处理,但瞬息万变的网民意见,突发的话题爆发很快让人手捉襟见肘。工程师们慢慢将开始利用计算机自动地对网络信息进行处理,意见挖掘由此应运而生。目前意见挖掘主要的研究对象是互联网上的海量文本信息,主要的任务包括网络文本的情感极性判别、评价对象抽取、意见摘要等。近年来,机器学习的发展让人们看到了意见挖掘的新希望。意见挖掘的智能化程度正在逐步提高。
评价对象(Opinion Targets)是指某段评论中所讨论的主题,具体表现为评论文本中评价词语所修饰的对象。如新闻评论中的某个人物、事件、话题,产品评论中某种产品的组件、功能、服务,电影评论中的剧本、特技、演员等。由于蕴含着极大的商业价值,所以现有的研究大部分集中于产品领域的评价对象的抽取,他们大多将评价对象限定在名词或名词短语的范畴内,进而对它们作进一步的识别。评价对象抽取是细粒度的情感分析任务,评价对象是情感分析中情感信息的一个重要组成部分。而且,这项研究的开展有助于为上层情感分析任务提供服务。因而评价对象抽取也就成为某些应用系统的必备组件,例如:
- 观点问答系统,例如就某个实体X,需要回答诸如“人们喜不喜欢X的哪些方面?”这样的问题。
- 推荐系统,例如系统需要推荐那些在某个属性上获得较好评价的产品。
- 观点总结系统,例如用户需要分别查看对某个实体X就某个方面Y的正面和负面评价。如图1所示为淘宝上某秋季女装的评价页面的标签。

图1:淘宝新款秋季女装的评价简述。其中“款式”、“材质”和“颜色”就是评价对象,红色表示对女装的正面评价,靛色表示负面评价。
这些任务的一个公共之处是,系统必须能够识别评论文本讨论的主题,即评价对象。评价对象作为意见挖掘的一个基本单元,一直是自然语言处理的热点。文章接下来将讨论评价对象抽取的研究现状。首先从名词的频率统计出发,阐述抽取评价对象的早期方法,然后在考虑评价对象与评价词的关系的基础上,讨论如何利用评价词发现已经出现和隐藏的评价对象、接着叙述经典的监督学习方法(隐马尔可夫方法和条件随机场)的优劣,最后详述了主题模型在评价对象抽取上的应用和展现。
研究现状
评价对象抽取属于信息抽取的范畴,是将非结构文本转换为结构化数据的一种技术。目前评价对象的抽取主要用于网络文本的意见挖掘。长如博客,短如微博都可以作为评价对象的抽取对象。在特定的情感分析环境下,所抽取的文本所处的领域往往能简化抽取的难度。一个最重要的特征就是文本中的名词。提取文本所描述的评价对象,并进一步地提取与评价对象相关的评价词,对于文本的自动摘要、归纳和呈现都有非常重要的意义。但需要注意的是评价词与评价对象的提取并没有什么先后关系,由于评价词与评价对象的种种联系。实践中往往会利用评价对象与评价词之间的特定映射来抽取信息。例如“这辆车很贵”中的“贵”是一个评价词(情感词),其评价的对象是车的价格。“贵”和“便宜”往往是用来描述商品的价格的。即使文本中没有出现“价格”,但依然可以判断其修饰的评价对象。第2小节将着重讨论这类隐式评价对象。前四节则探讨如何挖掘在文本中已经出现的评价对象。主流的方法有四种,分别是名词挖掘、评价词与对象的关联、监督学习方法和主题模型。
从频繁的名词开始
通过对大量商品评论的观察,可以粗略地发现评价对象大都是名词或者名词短语。Hu和Liu(2004)从某一领域的大量语料出发,先进行词性标记得到语料中的名词,再使用Apriori算法来发现评价对象。其具体步骤如下:
- 对句子进行词性标注,保留名词,去掉其它词性的词语。每个句子组成一个事务,用于第二步进行关联发现;
- 使用Apriori算法找出长度不超过3的频繁词集;
- 进行词集剪枝,去除稀疏和冗余的词集:
- 稀疏剪枝:在某一包含频繁词集f的句子s中,设顺序出现的词分别为,若任意两个相邻的词的距离不超过3,那么就称f在这一句子s中是紧凑的。若f至少在两条句子中是紧凑的,那么f就是紧凑的频繁词集。稀疏剪枝即是去除所有非紧凑的频繁词集;
- 冗余剪枝:设只包含频繁词集f,不包含f的超集的句子数目是频繁词集的p支持度。冗余剪枝会将p支持度小于最小p支持度的频繁词集去除。
这一方法尽管简单,但却非常有效。其原因在于人们对某一实体进行评价时,其所用词汇是有限的,或者收敛的,那么那些经常被谈论的名词通常就是较好的评价对象。Popescu和Etzioni(2005)通过进一步过滤名词短语使算法的准确率得到了提高。他们是通过计算名词短语与所要抽取评价对象的分类的点间互信息(Point Mutual Information,PMI)来评价名词短语。例如要在手机评价中抽取对象,找到了“屏幕”短语。屏幕是手机的一部分,属于手机分类,与手机的关系是部分与整体的关系。网络评论中常常会出现诸如“手机的屏幕…”、“手机有一个5寸的屏幕”等文本结构。Popescu和Etzioni通过在网络中搜索这类结构来确定名词短语与某一分类的PMI,继而过滤PMI较低的名词短语。PMI公式如下:
[Math Processing Error]
,其中a是通过Apriori算法发现的频繁名词短语,而d是a所在的分类。这样如果频繁名词短语的PMI值过小,那么就可能不是这一领域的评价对象。例如“线头”和“手机”就可能不频繁同时出现。Popescu和Etzioni还使用WordNet中的is-a层次结构和名词后缀(例如iness、ity)来分辨名词短语与分类的关系。
Blair-Goldensohn等人(2008)着重考虑了那些频繁出现在主观句的名词短语(包括名词)。例如,在还原词根的基础上,统计所有已发现的名词短语出现在主观句频率,并对不同的主观句标以不同的权重,主观性越强,权重越大,再使用自定义的公式对名词短语进行权重排序,仅抽取权重较高的名词短语。
可以发现众多策略的本质在于统计频率。Ku等人(2006)在段落和文档层面上分别计算词汇的TF-IDF,进而提取评价对象。Scaffidi等人(2007)通过比较名词短语在某一评论语料中出现的频率与在普通英文语料中的不同辨别真正有价值的评价对象。Zhu等人(2009)先通过Cvalue度量找出由多个词组成的评价对象,建立候选评价对象集,再从评价对象种子集出发,计算每个候选评价对象中的词的共现频率,接着不断应用Bootstrapping方法挑选候选评价对象。Cvalue度量考虑了多词短语t的频率f(t)、长度|t|以及包含t的其它短语集合[Math Processing Error]。计算公式如下:
[Math Processing Error]
评价词与对象的关系
评价对象与评价意见往往是相互联系的。它们之间的联系可以被用于抽取评价对象。例如情感词可以被用于描述或修饰不同的评价对象。如果一条句子没有频繁出现的评价对象,但却有一些情感词,那么与情感词相近的名词或名词短语就有可能是评价对象。Hu和Liu(2004)就使用这一方法来提取非频繁的评价对象,Blair-Goldenshohn等人(2008)基于情感模式也使用相似的方法。
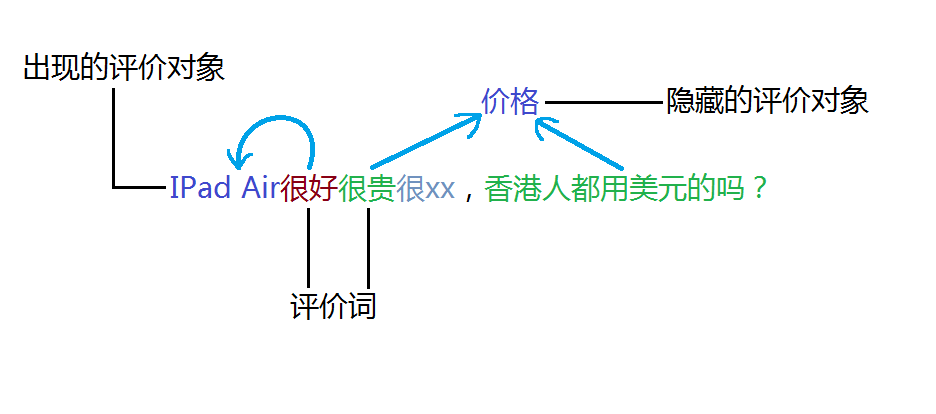
图2:利用评价词发现评价对象,甚至是隐藏的评价对象
举例来说,“这个软件真有趣!”由于“有趣”是一个情感词,所以“软件”即被抽取作为评价对象。这一方法常常被用于发现评论中重要或关键的评价对象,因为如果一个评价对象不被人评价或者阐述观点,那么它也就不大可能是重要的评价对象了。在Hu和Liu(2004)中定义了两种评价对象:显式评价对象和隐式评价对象。Hu和Liu将名词和名词短语作为显式评价对象,例如“这台相机的图像质量非常不错!”中的“图像质量”,而将所有其它的表明评价对象的短语称为隐式评价对象,这类对象需要借由评价词进行反向推导。形容词和动词就是最常见的两种推导对象。大多数形容词和动词都在描述实体属性的某一方面,例如“这台相机是有点贵,但拍得很清晰。”“贵”描述的是“价格”,“拍”和“清晰”描述的是“图像质量”。但这类评价对象在评论中并没有出现,它隐含在上下文中。
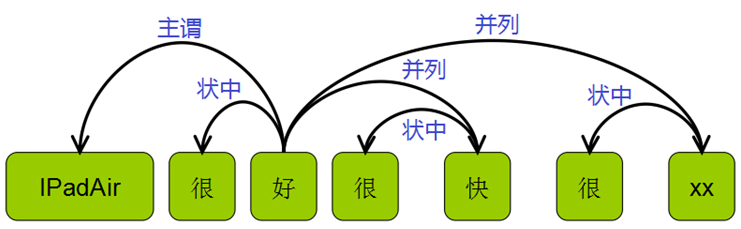
图3:依存句法示例
如果评价词所对应的评价对象出现在评论中,评价词与评价对象之间往往存在着依存关系。Zhuang等人(2006)、Koaryashi等人(2006)、Somasundaran和Wiebe(2009)、Kessler和Nicolov(2009)通过解析句子的依存关系以确定评价词修饰的对象。Qiu等人(2011)进一步将这种方法泛化双传播方法(double-propagation),同时提取评价对象和评价词。注意到评价对象可能是名词或动词短语,而不只是单个词,Wu等人(2009)通过句子中短语的依存关系来寻找候选评价对象,再然后通过语言模型过滤评价对象。
尽管显式评价对象已经被广泛地研究了,但如何将隐式评价对象映射到显式评价对象仍缺乏探讨。Su等人(2008)提出一种聚类方法来映射由情感词或其短语表达的隐式评价对象。这一方法是通过显式评价对象与情感词在某一句子中的共现关系来发现两者的映射。Hai等人(2011)分两步对共同出现的情感词和显式评价对象的关联规则进行挖掘。第一步以情感词和显式评价对象的共现频率为基础,生成以情感词为条件,以显式评价对象为结果的关联规则。第二步对关联规则进行聚类产生更加鲁棒的关联规则。
监督学习方法
评价对象的抽取可以看作是信息抽取问题中的一个特例。信息抽取的研究提出了很多监督学习算法。其中主流的方法根植于序列学习(Sequential Learning,或者Sequential Labeling)。由于这些方法是监督学习技术,所以事先需要有标记数据进行训练。目前最好的序列学习算法是隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF)。Jin和Ho等人使用词汇化的HMM模型来学习抽取评价对象和评价词的模式。Jakob和Gurevych则在不同领域上进行CRF训练,以获得更加领域独立的模式,其使用的特征有词性、依存句法、句距和意见句。Li等人(2010)整合了Skip-CRF和Tree-CRF来提取评价对象,这两种CRF的特点在于其既能学习词序列,也能发现结构特征。除了这两种主流的序列标注技术外。Kobayashi等人(2007)先使用依赖树发现候选评价对象和评价词对,接着使用树状分类方法去学习这些候选对,并对其分类。分类的结果就在于判断候选对中的评价对象与评价词是否存在评价关系。分类所依据的特征包括上下文线索、共现频率等。Yu等人(2011)使用单类SVM(one-class SVM,Manevitz和Yousef,2002)这一部分监督学习方法来提取评价对象。单类SVM的特点在于其训练所需的样本只用标注某一类即可。他们还对相似的评价对象进行了聚类,并根据出现的频率和对评论评分的贡献进行排序,取得较优质的评价对象。Kovelamudi等人(2011)在监督学习的过程中加入了维基百科的信息。

图4:评价对象标注示例,进而可用于序列学习
虽然监督学习在训练数据充足的情况下可以取得较好的结果,但其未得到广泛应用的原因也在于此。在当前互联网信息与日俱增的情况下,新出现的信息可能还未来得及进行人工标记成为训练语料,就已经过时了。而之前标记过的语料又将以越来越快的速度被淘汰。尽管不断涌现出各种半监督学习方法试图弥补这一缺憾,但从种子集开始的递增迭代学习会在大量训练后出现偏差,而后期的人工纠偏和调整又是需要大量的工作,且维护不易。有鉴于此,虽然学术界对在评价对象抽取任务上使用监督学习方法褒贬不一,但在工业界的实现成果却不大。
主题模型(Topic Model)
近年来,统计主题模型逐渐成为海量文档主题发现的主流方法。主题建模是一种非监督学习方法,它假设每个文档都由若干个主题构成,每个主题都是在词上的概率分布,最后输出词簇的集合,每个词簇代表一个主题,是文档集合中词的概率分布。一个主题模型通常是一个文档生成概率模型。目前主流的主题模型有两种:概率潜在语义模型(Probabilistic Latent Semantic Analysis,PLSA)和潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)。Mei等人(2007)提出了一种基于pLSA的联合模型以进行情感分析,这一模型的特点在于是众多模型的混合,包括主题模型,正面情感模型和负面情感模型。如此多的模型自然是需要较多数据进行学习。这之后的其它模型大多是利用LDA挖掘评价对象。

图5:LDA示例
从技术上讲,主题模型是基于贝叶斯网络的图模型。但却可以被扩展用于建模多种信息。在情感分析中,由于每种意见都包含一个评价对象,那么就可以使用主题模型进行建模。但主题与评价对象还是有些不同的,主题同时包含了评价对象和情感词。就情感分析来说需要被分割这两者。这可以通过同时对评价对象和情感词建模来完成。还需注意的是主题模型不仅能发现评价对象,还能对评价对象进行聚类。
Titov和McDonald(2008)开始发现将LDA直接应用全局数据可能并不适用于识别评价对象。其原因在于LDA依靠文档中词共现程度和主题分布的不同来发现主题及其词概率分布。然而,某一商品下的评论往往都是同质的,也就是都是在讨论同一个商品,这使得主题模型在挖掘评价对象上表现不好,仅能在发现实体上发挥些余热(不同品牌和产品名称)。Titov和McDonald因此提出了多粒度主题模型。在全局数据上利用主题模型发现讨论实体,与此同时也将主题模型应于文档中的连续的数条句子。发现得到的某一类评价对象实际上是一个一元语言模型,即词的多项分布。描述相同评价对象的不同词被自动聚类。然而这一方法并没有将其中的评价词(情感词)加以分离。
通过扩展LDA,Lin和He(2009)提出了一个主题和情感词的联合模型,但仍未显式地分开评价对象和评价词。Brody和Elhadad(2010)认为可以先使用主题模型识别出评价对象,再考虑与评价对象相关的形容词作为评价词。Li等人(2010)为了发现评价对象及其褒贬评价词,提出了Sentiment-LDA和Dpeendency-sentiment-LDA两种联合模型,但既没有独立发现评价对象,也没有将评价对象与评价词分开。Zhao等人(2010)提出MaxEnt-LDA(Maximum Entrpy LDA)来为评价对象和评价词联合建模,并使用句法特征辅助分离两者。他们使用多项分布的指示变量来分辨评价对象、评价词和背景词(即评价对象和评价词以外的词),指示变量使用最大熵模型来训练其参数。Sauper等人(2011)则试图通过加入HMM模型达到区分评价对象、评价词和背景词的目的。但他们只应用在文本的短片段里。这些短片段是从评价论中抽取出的,例如“这电池正是我想要的”。这与Griffiths等(2005)于2005年提出的HMM-LDA颇有异曲同工之妙。Mukherjee和Liu(2012)从用户提供的评价对象种子集开始,应用半监督联合模型不断迭代,产生贴近用户需要的评价对象。联合模型的其它改进见于Liu等人(2007),Lu和Zhai(2008)和Jo和Oh(2011)。
在数据量巨大的情况下,抽取得到的评价对象往往也比较多。为了发现较为重要的评价对象,Titov和McDonald(2008)在从评论中找出评价对象的同时,还预测用户对评价对象的评价等级,并且抽取部分片段作为等级参考。Lu等人(2009)利用结构pLSA对短文本中各短语的依赖结构进行建模,并结合短评论的评价等级预测评论对象的评价等级。Lakkaraju等人在HMM-LDA(Griffiths等人,2005)的基础上提出了一系列同时兼顾在词序列和词袋的联合模型,其特点在于能发现潜在的评价对象。他们与Sauper等人(2011)一样都考虑了句法结构和语义依赖。同样利用联合模型发现和整理评价对象,并预测评价等级的还有Moghaddam和Ester(2011)。
在实际应用中,主题模型的某些缺点限制了它在实际情感分析中的应用。其中最主要的原因在于它需要海量的数据和多次的参数微调,才能得到合理的结果。另外,大多数主题模型使用Gibbs采样方法,由于使用了马尔可夫链蒙特卡罗方法,其每次运行结果都是不一样的。主题模型能轻易地找到在海量文档下频繁出现的主题或评价对象,但却很难发现那些在局部文档中频繁出现的评价对象。而这些局部频繁的评价对象却往往可能与某一实体相关。对于普通的全局频繁的评价对象,使用统计频率的方法更容易获得,而且还可以在不需要海量数据的情况下发现不频繁的评价对象。也就是说,当前的主题建模技术对于实际的情感分析应用还不够成熟。主题模型更适用于获取文档集合中更高层次的信息。尽管如此,研究者们对主题建模这一强大且扩展性强的建模工具仍抱有很大期望,不断探索着。其中一个努力的方向是将自然语言知识和领域知识整合进主题模型(Andrzejewski和Zhu,2009;Andrejewski等人,2009;Mukherjee和Liu,2012;Zhai等人,2011)。这一方向的研究目前还过于依赖于统计并且有各自的局限性。未来还需要在各类各领域知识间做出权衡。
其他方法
除了以上所谈的主流方法外,某些研究人员还在其它方法做了尝试。Yi等人(2003)使用混合语言模型和概率比率来抽取产品的评价对象。Ma和Wan(2010)使用中心化理论和非监督学习。Meng和Wang(2009)从结构化的产品说明中提取评价对象。Kim和Hovy(2006)使用语义角色标注。Stoyanov和Cardie(2008)利用了指代消解。
总结
大数据时代的到来不仅给机器学习带来了前所未有的机遇,也带来了实现和评估上的各种挑战。评价对象抽取的任务在研究初期通过名词的频率统计就能大致得到不错的效果,即使是隐含的对象也能通过评价词的映射大致摸索出来,但随着比重越来越大的用户产生的文本越来越口语化,传统的中文分词与句法分析等技术所起到的作用将逐渐变小,时代呼唤着更深层次的语义理解。诸如隐马尔可夫和条件随机场这样监督学习方法开始被研究者们应用到评价对象的抽取上,在训练数据集充足的情况下,也的确取得了较好的效果。然而仅靠人工标注数据是无法跟上当前互联网上海量的文本数据,像LDA这样扩展性好的无监督方法越来越受到人们的关注。但LDA目前还存在着参数多,结果不稳定等短板,而且完全的无监督方法也无法适应各种千差万别的应用背景下。展望未来,人们希望能诞生对文本——这一人造抽象数据——深度理解的基础技术,或许时下火热的深度学习(Deep Learning)就是其中一个突破点。
参考文献
- Hu M, Liu B. Mining and summarizing customer reviews[C]//Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2004: 168-177.
- Popescu A M, Etzioni O. Extracting product features and opinions from reviews[M]//Natural language processing and text mining. Springer London, 2007: 9-28.
- Blair-Goldensohn S, Hannan K, McDonald R, et al. Building a sentiment summarizer for local service reviews[C]//WWW Workshop on NLP in the Information Explosion Era. 2008.
- Ku L W, Liang Y T, Chen H H. Opinion Extraction, Summarization and Tracking in News and Blog Corpora[C]//AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs. 2006: 100-107.
- Scaffidi C, Bierhoff K, Chang E, et al. Red Opal: product-feature scoring from reviews[C]//Proceedings of the 8th ACM conference on Electronic commerce. ACM, 2007: 182-191.
- Zhu J, Wang H, Tsou B K, et al. Multi-aspect opinion polling from textual reviews[C]//Proceedings of the 18th ACM conference on Information and knowledge management. ACM, 2009: 1799-1802.
- Zhuang L, Jing F, Zhu X Y. Movie review mining and summarization[C]//Proceedings of the 15th ACM international conference on Information and knowledge management. ACM, 2006: 43-50.
- Kobayashi N, Iida R, Inui K, et al. Opinion Mining on the Web by Extracting Subject-Aspect-Evaluation Relations[C]//Proceedings of AAAI Spring Sympoia on Computational Approaches to Analyzing Weblogs. AAAI-CAAW, 2006.
- Somasundaran S, Wiebe J. Recognizing stances in online debates[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 1-Volume 1. Association for Computational Linguistics, 2009: 226-234.
- Kessler J S, Nicolov N. Targeting Sentiment Expressions through Supervised Ranking of Linguistic Configurations[C]//ICWSM. 2009.
- Qiu G, Liu B, Bu J, et al. Opinion word expansion and target extraction through double propagation[J]. Computational linguistics, 2011, 37(1): 9-27.
- Wu Y, Zhang Q, Huang X, et al. Phrase dependency parsing for opinion mining[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 3-Volume 3. Association for Computational Linguistics, 2009: 1533-1541.
- Su F, Markert K. From words to senses: a case study of subjectivity recognition[C]//Proceedings of the 22nd International Conference on Computational Linguistics-Volume 1. Association for Computational Linguistics, 2008: 825-832.
- Hai Z, Chang K, Kim J. Implicit feature identification via co-occurrence association rule mining[M]//Computational Linguistics and Intelligent Text Processing. Springer Berlin Heidelberg, 2011: 393-404.
- Jin W, Ho H H, Srihari R K. A novel lexicalized HMM-based learning framework for web opinion mining[C]//Proceedings of the 26th Annual International Conference on Machine Learning. 2009: 465-472.
- Jakob N, Gurevych I. Extracting opinion targets in a single-and cross-domain setting with conditional random fields[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2010: 1035-1045.
- Li F, Han C, Huang M, et al. Structure-aware review mining and summarization[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Association for Computational Linguistics, 2010: 653-661.
- Kobayashi N, Inui K, Matsumoto Y. Extracting Aspect-Evaluation and Aspect-Of Relations in Opinion Mining[C]//EMNLP-CoNLL. 2007: 1065-1074.
- Yu J, Zha Z J, Wang M, et al. Domain-assisted product aspect hierarchy generation: towards hierarchical organization of unstructured consumer reviews[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2011: 140-150.
- Manevitz L M, Yousef M. One-class SVMs for document classification[J]. The Journal of Machine Learning Research, 2002, 2: 139-154.
- Kovelamudi S, Ramalingam S, Sood A, et al. Domain Independent Model for Product Attribute Extraction from User Reviews using Wikipedia[C]//IJCNLP. 2011: 1408-1412.
- Hofmann T. Probabilistic latent semantic indexing[C]//Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 1999: 50-57.
- Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. the Journal of machine Learning research, 2003, 3: 993-1022.
- Mei Q, Ling X, Wondra M, et al. Topic sentiment mixture: modeling facets and opinions in weblogs[C]//Proceedings of the 16th international conference on World Wide Web. ACM, 2007: 171-180.
- Titov I, McDonald R. Modeling online reviews with multi-grain topic models[C]//Proceedings of the 17th international conference on World Wide Web. ACM, 2008: 111-120.
- Lin C, He Y. Joint sentiment/topic model for sentiment analysis[C]//Proceedings of the 18th ACM conference on Information and knowledge management. ACM, 2009: 375-384.
- Brody S, Elhadad N. An unsupervised aspect-sentiment model for online reviews[C]//Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2010: 804-812.
- Li F, Huang M, Zhu X. Sentiment Analysis with Global Topics and Local Dependency[C]//AAAI. 2010.
- Zhao W X, Jiang J, Yan H, et al. Jointly modeling aspects and opinions with a MaxEnt-LDA hybrid[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2010: 56-65.
- Sauper C, Haghighi A, Barzilay R. Content models with attitude[C]. Association for Computational Linguistics, 2011.
- Griffiths T L, Steyvers M, Blei D M, et al. Integrating topics and syntax[C]//Advances in neural information processing systems. 2004: 537-544.
- Mukherjee A, Liu B. Aspect extraction through semi-supervised modeling[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1. Association for Computational Linguistics, 2012: 339-348.
- Liu Y, Huang X, An A, et al. ARSA: a sentiment-aware model for predicting sales performance using blogs[C]//Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2007: 607-614.
- Lu Y, Zhai C. Opinion integration through semi-supervised topic modeling[C]//Proceedings of the 17th international conference on World Wide Web. ACM, 2008: 121-130.
- Jo Y, Oh A H. Aspect and sentiment unification model for online review analysis[C]//Proceedings of the fourth ACM international conference on Web search and data mining. ACM, 2011: 815-824.
- Lu Y, Zhai C X, Sundaresan N. Rated aspect summarization of short comments[C]//Proceedings of the 18th international conference on World wide web. ACM, 2009: 131-140.
- Lakkaraju H, Bhattacharyya C, Bhattacharya I, et al. Exploiting coherence for the simultaneous discovery of latent facets and associated sentiments[J]. 2011.
- Moghaddam S, Ester M. Opinion digger: an unsupervised opinion miner from unstructured product reviews[C]//Proceedings of the 19th ACM international conference on Information and knowledge management. ACM, 2010: 1825-1828.
- Andrzejewski D, Zhu X. Latent Dirichlet Allocation with topic-in-set knowledge[C]//Proceedings of the NAACL HLT 2009 Workshop on Semi-Supervised Learning for Natural Language Processing. Association for Computational Linguistics, 2009: 43-48.
- Andrzejewski D, Zhu X, Craven M. Incorporating domain knowledge into topic modeling via Dirichlet forest priors[C]//Proceedings of the 26th Annual International Conference on Machine Learning. ACM, 2009: 25-32.
- Zhai Z, Liu B, Xu H, et al. Constrained LDA for grouping product features in opinion mining[M]//Advances in knowledge discovery and data mining. Springer Berlin Heidelberg, 2011: 448-459.
- Yi J, Nasukawa T, Bunescu R, et al. Sentiment analyzer: Extracting sentiments about a given topic using natural language processing techniques[C]//Data Mining, 2003. ICDM 2003. Third IEEE International Conference on. IEEE, 2003: 427-434.
- Ma T, Wan X. Opinion target extraction in Chinese news comments[C]//Proceedings of the 23rd International Conference on Computational Linguistics: Posters. Association for Computational Linguistics, 2010: 782-790.
- Meng X, Wang H. Mining user reviews: from specification to summarization[C]//Proceedings of the ACL-IJCNLP 2009 Conference Short Papers. Association for Computational Linguistics, 2009: 177-180.
- Kim S M, Hovy E. Extracting opinions, opinion holders, and topics expressed in online news media text[C]//Proceedings of the Workshop on Sentiment and Subjectivity in Text. Association for Computational Linguistics, 2006: 1-8.
- Stoyanov V, Cardie C. Topic identification for fine-grained opinion analysis[C]//Proceedings of the 22nd International Conference on Computational Linguistics-Volume 1. Association for Computational Linguistics, 2008: 817-824.
原创文章,作者:199it,如若转载,请注明出处:https://www.iyunying.org/seo/dataanalysis/38652.html
