希娜和她的研究伙伴从名为“Yummly”的应用中下载了200个菜系超过15万份食谱,构建了食谱数据库。他们着重研究了其中82个菜系中超过100份食谱,这些食谱中用到的食材超过了3000种。
之后,他们计算了不同食谱中的碳水化合物、蛋白质和脂肪含量,来标注每道菜的营养价值。同时,他们还搜集了不同国家的其他数据,包括医疗保健支出占GDP比重、肥胖率和净迁移率等,然后利用数据挖掘和机器智能技术发掘数据的信息点。
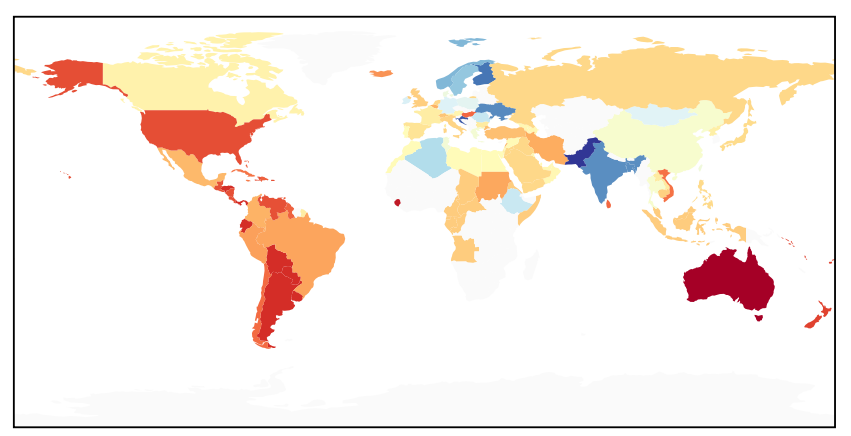
结果显示,移民大国的饮食多样性最高,如美国和澳大利亚。这些国家移民数量最多,菜肴种类也最多。“这主要是因为移民从不同国家带来了他们的烹饪方法和特色菜肴,极大的丰富了当地的饮食多样性。”
这种情况出现的原因还不得而知。“可能是因为这两个国家的厨师厨艺高超,可以用有限的食材制作出复杂而精美的食物,”希娜推测道。还有一种可能的原因是中国和印度两国历史悠久,所以菜肴的制作有更长的时间来进化发展。
该团队还通过比较选用的食材,总结了不同菜系的相似点。结果显示,一些食材是最具有区分性的。比如,马苏里拉奶酪只有在意大利菜里才会出现,而五味粉葛拉姆马萨拉(一种咖喱粉)是印度菜的标志。
此项研究还总结了一个地区菜系营养价值和居民健康状况的关联性。结果显示,一个地区的肥胖率和菜肴中糖与碳水化合物的含量关联度很高。饮食中蛋白质含量高的地区居民患健康疾病的概率要小的多。
这是一项有意思的研究,但是也存在一些需要注意的问题。最突出的问题就是该团队搜集的数据的局限性。从Yummly这个手机应用上下载的菜谱真的具有代表性吗?
举例来说,伦敦的印度餐厅里使用的咖喱和印度本土使用的有很大区别。在Yummly上,两种咖喱都被标注出来了吗?印度咖喱种类根本不能用单一标签来标注。
尽管有一些小问题,这样的数据挖掘依然对世界饮食具有一定参考价值,萨瓦兰也会觉得大吃一惊吧。
来自:灯塔大数据
原创文章,作者:爱运营,如若转载,请注明出处:https://www.iyunying.org/seo/dataanalysis/86247.html
